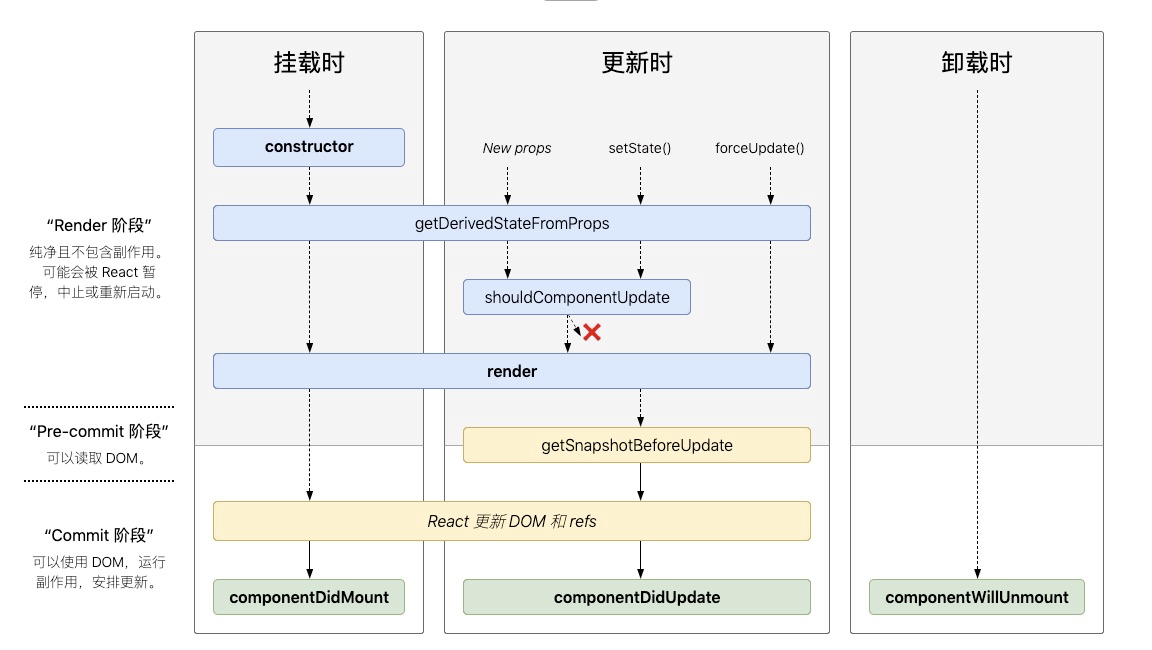
Hooks是React 16.8版本的新增特性,它的出现让我们可以不再写class组件来维护组件的内部状态。
useMemo
1 const memoizedValue = useMemo(() =>
useMemo缓存计算结果,它接收一个计算的过程(回调函数,它将返回结果)和依赖项数据,返回一个memoized值。当依赖项发生变化的时候,回调函数会重新计算。
useCallback
1 2 3 4 5 6 const memoizedCallback = useCallback( () => { doSomething(a, b); }, [a, b], );
useCallback缓存一个函数体,它接收回调参数和依赖项数组,返回一个 memoized 回调函数,只有依赖项发生变化的时候才会返回一个新的函数。
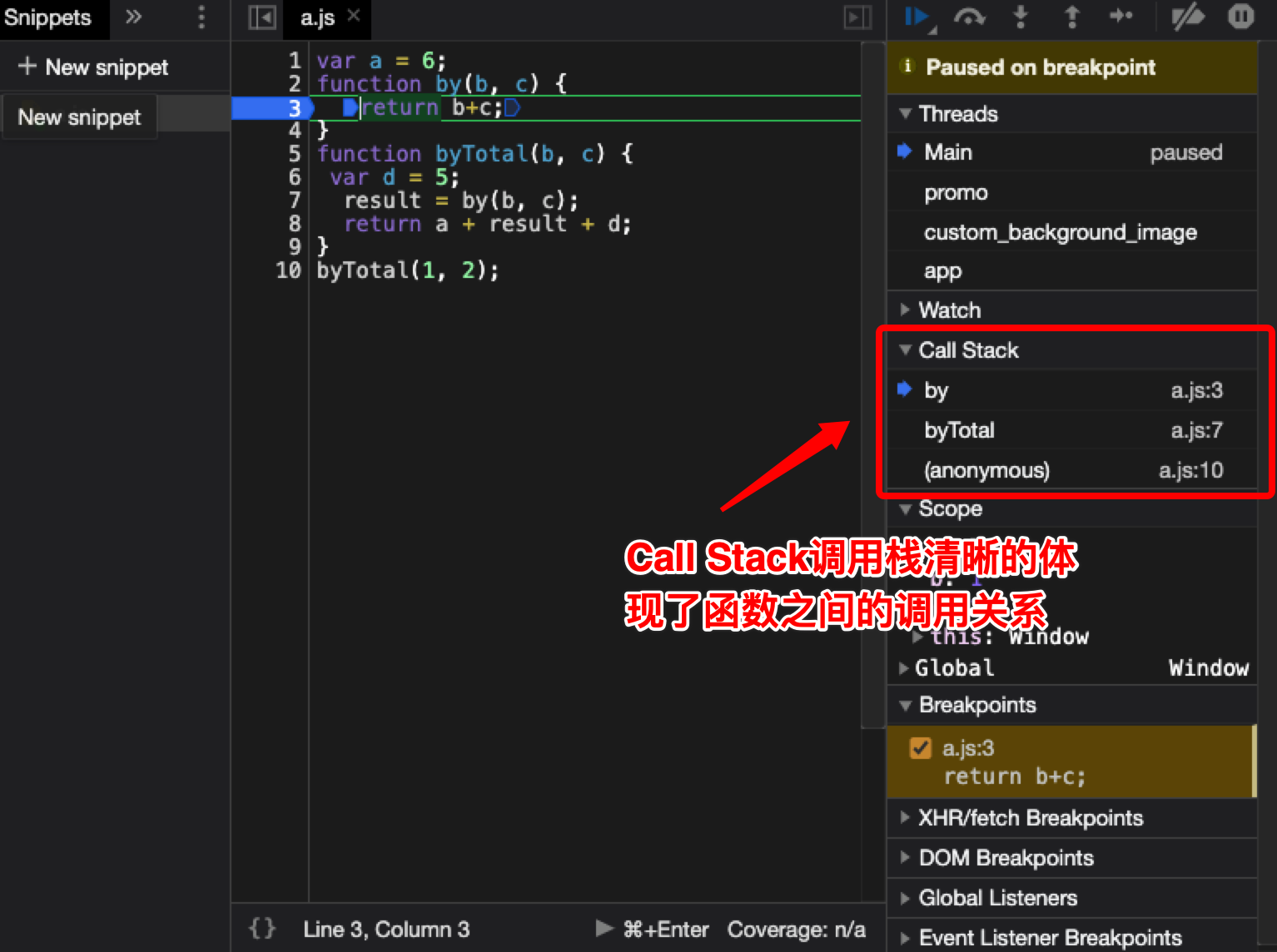
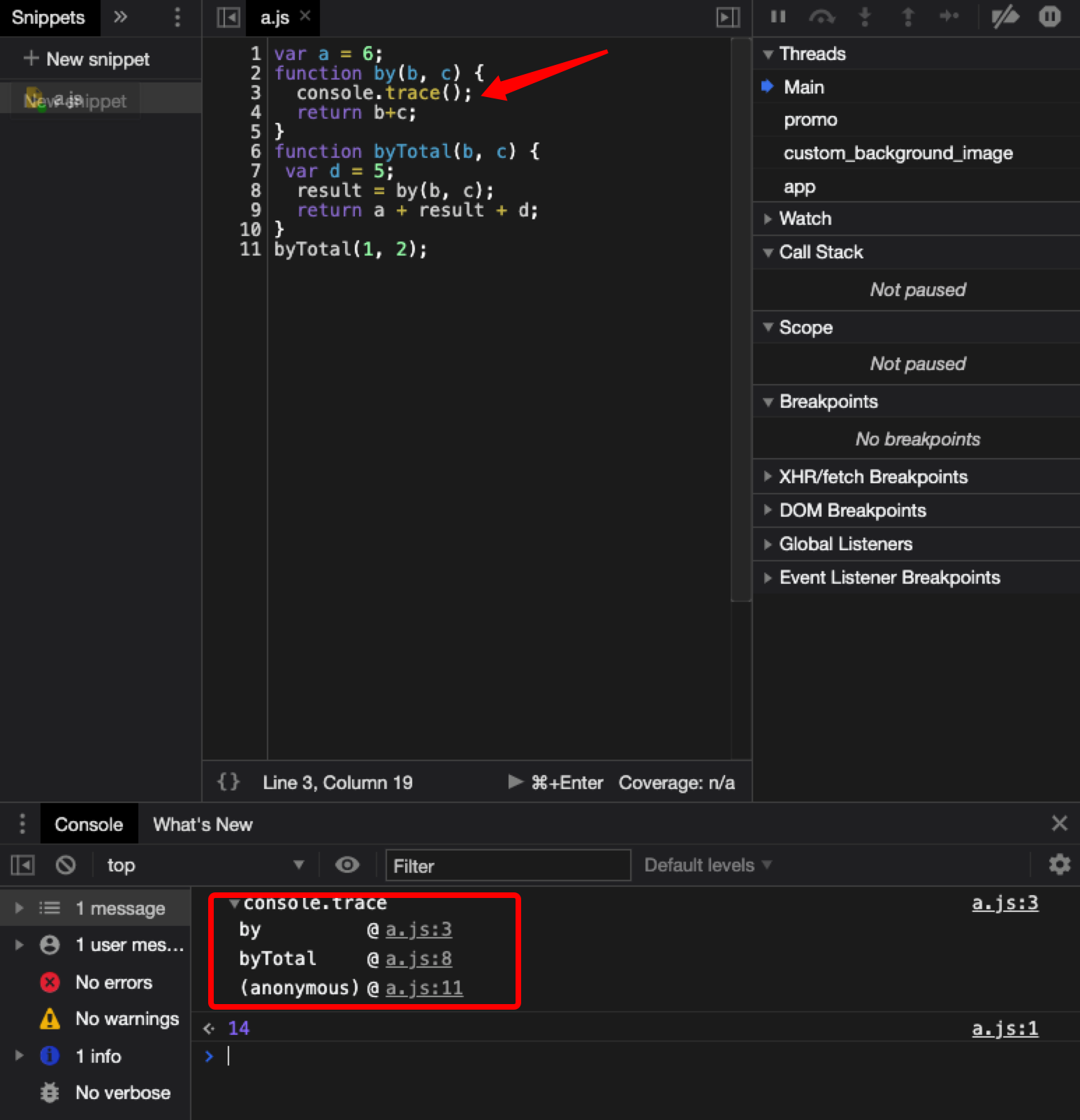
那么是不是所有场景下使用useCallback都能达到性能优化的效果呢。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 function Example ( const [value, setValue] = useState(); const onChange = (e ) => { setValue(e.target.value); }; return <input value ={value} onChange ={onChange} /> } ---------------------------------------------------------------------------------------------- const onChange = useCallback(e => setValue(e.target.value); }, []); const onChange = (e ) => { setValue(e.target.value); }; const onChangeMemoized = useCallback(onChange, []);
我们给一个input框传入onChange方法,当我们将它加上useCallback后,我们会发现这个方式除了定义了onChange方法外,还有调用useCallback产生了额外的开销,导致适得其反。
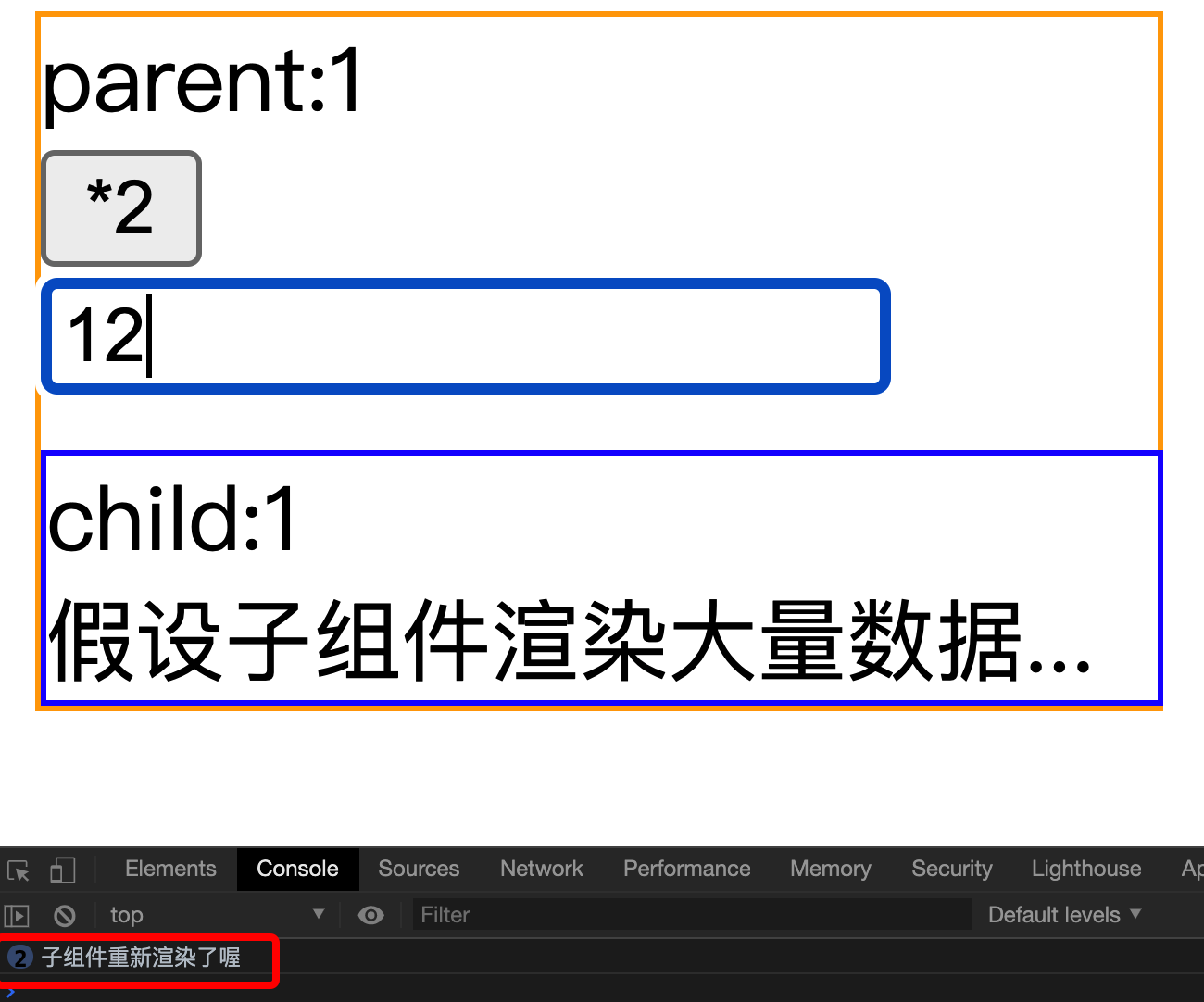
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 const BigData = ({ showNum } ) => { const [num, setNum] = useState(() => console .log("子组件重新渲染了喔" ); useEffect(() => setNum(showNum()); }, [showNum]); return ( <div className='BigData' > {'child:' +num} <br></br> {'假设子组件渲染大量数据...'} </ div> ); }; export default React.memo(BigData)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import BigData from './Child' const App = () => const [value, setValue] = useState('' ); const [num, setNum] = useState(1 ); const showNum = useCallback(() =>return num; }, [num]); return ( <div className='app' > <div>{'parent:' + num}</div> <div> <button onClick={() => setNum(num * 2)}>*2</ button> </div> <input value={value} onChange={event => setValue(event.target.value)} / > <BigData showNum={showNum} /> </div> ); }
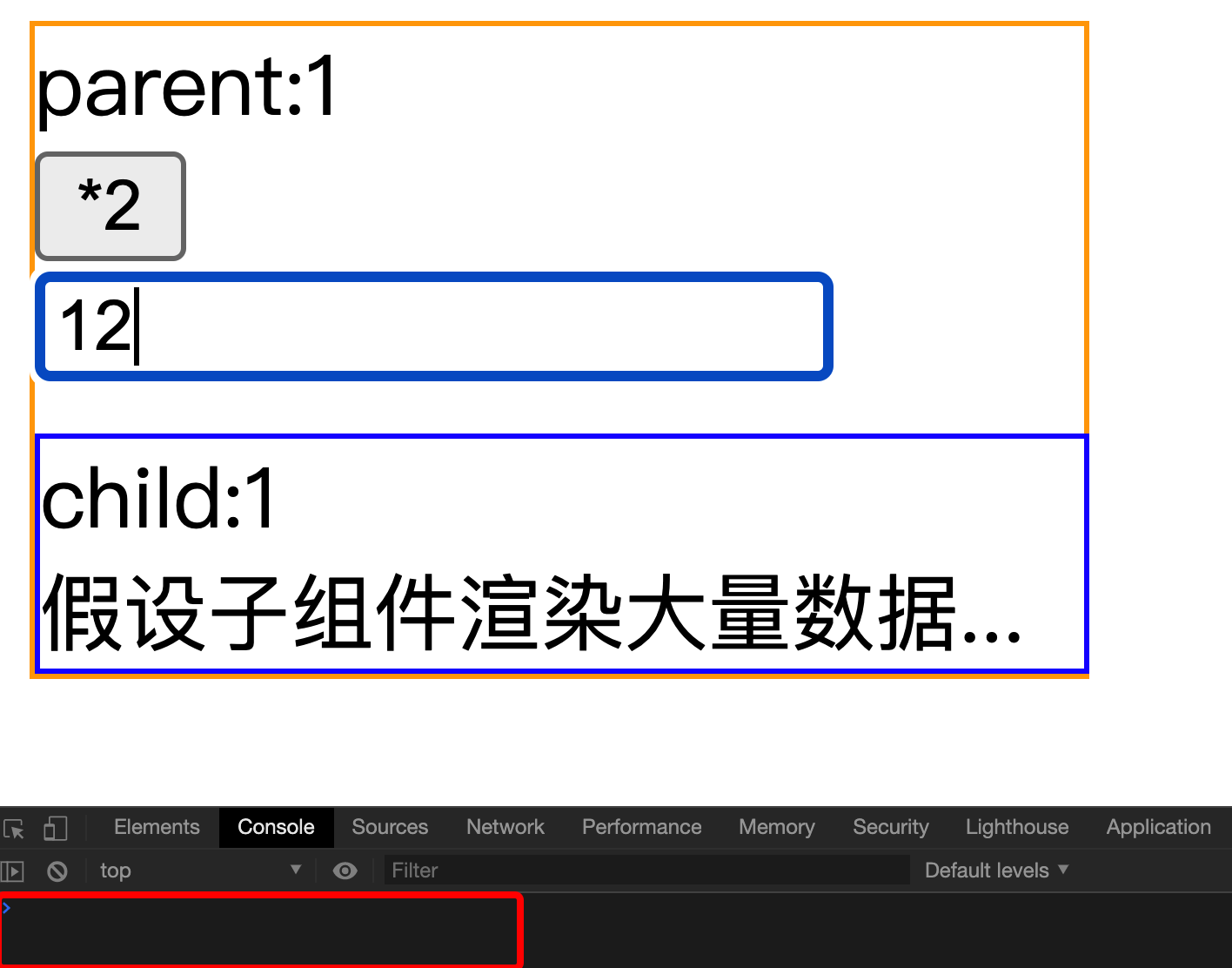
我们假设一个场景,子组件需要展示大量的数据,它从父组件接收一个函数。在很多时候,父组件更新的时候,我们不需要子组件的更新。可能大家会给子组件包装到React.memo中(作用可参考shouldComponentUpdate(),但仅适用于函数组件),来保证props相同的情况下不重复渲染组件。但是函数式组件更新的时候函数会重新声明,引用发生了变化。而React.memo函数只会浅比较props,因此子组件仍然会重新渲染。此时我们给要传入子组件的函数加上useCallback来保证函数引用的相等,从而达到子组件不重复渲染的效果,实现性能优化。
如果加上useCallback
那么useMemo其实也是类似的,当我们需要给子组件传入一个引用类型的对象时,父组件重新渲染会导致值的引用发生变化。如果此时我们不需要重新渲染子组件时,可以用useMemo来记住这个值。
1 2 3 4 5 6 7 const Example = () => const value = useMemo(() => compute(num) }, [num]); return <BigData value ={value} /> }
我们假设渲染子组件的开销较大(又是一个渲染大量数据的组件2333),那么value(返回值为引用类型)的引用变化而依赖项num没有变化时,我们可能不想子组件重新渲染。因此可以用useMemo来避免Example组件的渲染导致compute方法重新计算。此时value的引用不会发生变化,子组件不会重新渲染。
1 2 3 4 5 6 7 8 9 10 11 const ChildMemo = ({ childData, onClick} ) => { console .log('我是子组件,我渲染了he' ) return ( <div> <span >{'子组件:' +childData.name}</span> <button onClick={() => onClick('变身2333')}>改变name</ button> </div> ); } export default React.memo(ChildMemo);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 const Example = () => const [num, setNum] = useState(0 ); const [name, setName] = useState('子组件' ); return ( <> <span>number:{num}</span> <button onClick={(e) => { setNum(num + 1) }}>加1</ button> <ChildMemo childData={ useMemo(() => name, color: name.indexOf('2333' ) !== -1 ? 'blue' : 'purple' }), [name]) } onClick={useCallback((newName ) => setName(newName), [])} /> </> ) }
当我们点击按钮时,如果childData返回值不加上useMemo,由于传入的参数为引用类型,引用变化会导致子组件的重新渲染。这种场景和上一个例子相似,只不过传入的参数不是一个方法,而是一个引用类型的值了。用useMemo可以保证在依赖项不变的时候,传入子组件的是同一个引用。
关于useMemo,还有一种情况我们可以使用。当一个函数的开销很大时(有较复杂的计算过程),我们可以用useMemo来记住它的返回值,这样可以避免性能消耗较高的重复计算。
1 2 3 4 5 6 7 8 9 10 11 const Example = () => const result = useMemo(() => function expensiveCompute (value ) } return ( <div> {result} </div> ) }
加上useMemo后,虽然组件在重新渲染的时候将会重新定义这个开销较大的函数,但是它只会在被需要的时候才会被调用。当依赖项不变时,该方法将返回之前已经计算好的值。
总结